Load Balancing and Health Checks


It's pretty common to want to load balance a web application across multiple nodes. The canonical implementation looks something like this:
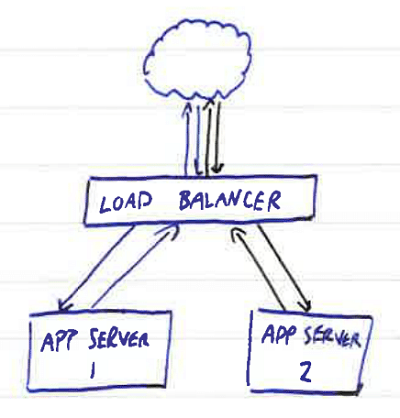
Traffic comes in from the public Internet to the load balancer, which then distributes it amongst the available application servers. There are various tricks you can employ on top of that; consistently directing clients to the same server to keep caches warm, dynamic balancing based on CPU load, failover to standby nodes and so on. But the principle remains the same - using multiple servers to spread the load and serve more requests (scaling horizontally).
There's another common use case beyond merely spreading the load to multiple servers, and that's redundancy. If you have one server and it goes down, your site goes down with it. If you have two servers and one goes down, then in theory the site is still up but with reduced capacity. Let's take a look at that scenario:
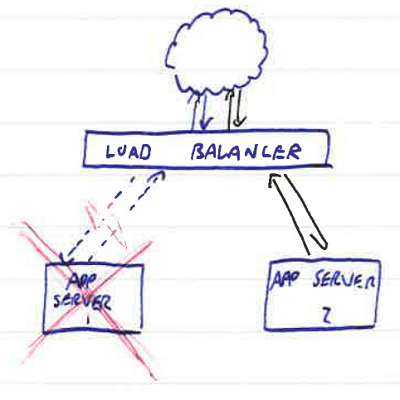
What actually happens with naive load balancing is that you still have a problem. Depending on the balancing strategy, the above situation with one of two servers down results in either 50% of requests failing for 100% of clients, or 100% of requests failing for 50% of clients. This happens because the naive load balancing just distributes traffic evenly between multiple nodes - it doesn't know whether the node it's directing traffic to is working correctly or not.
The solution is to make the load balancer keep track of whether a site in the list is considered working or broken. We do this with a health check. This can be as simple as pinging the server to see if it's up, but more useful is a small endpoint that returns a 200 OK message if the node is fit to serve requests:
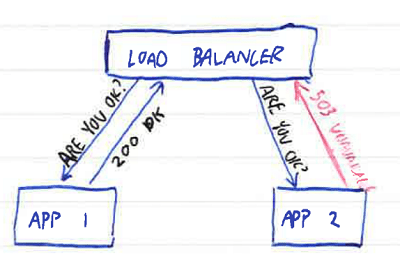
The load balancer periodically makes requests to this endpoint, and inspects the results. If a node starts returning errors or fails to respond, the load balancer removes it from rotation and therefore doesn't direct traffic to it. This reduces capacity but your site stays up; unless the servers were saturated before one of them went down, users see no degradation of service. (If you need some sort of HA guarantee at peak load, it logically follows that you need enough spare capacity to handle a server failure at that peak).
This is fine for simple static web pages or small applications operating entirely in one process. But realistic production workloads are more complicated than that - behind the tip of the application endpoints are databases, other services, queues and whatever else makes up the application as a whole:
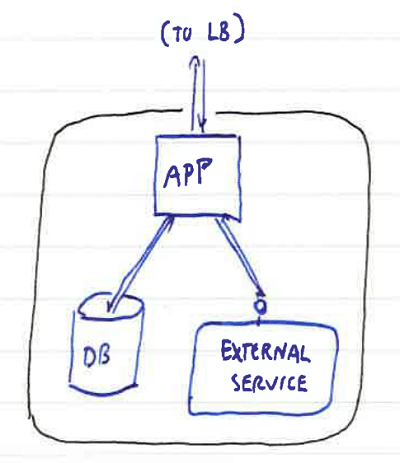
If our health check is a simple 200 OK if the application is responding to requests, what happens in the following scenario, where a network link outbound from the server fails?
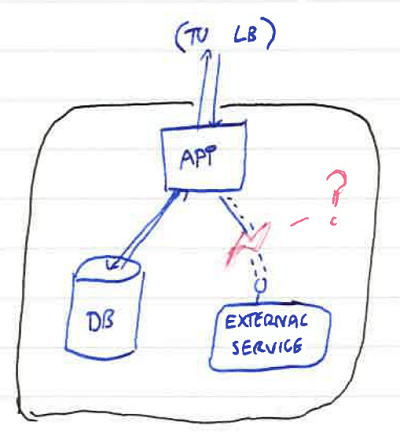
Your application will still report a 200 OK back up to the load balancer (because it's running) but anything which calls out to that external service will fail. If this is critical for the application to operate correctly, you end up back in the situation where a proportion of requests fail even though other servers in the rotation are operating normally.
To resolve this, you need to make your health check more robust:
- Make a call to each critical service (this may include internal modules)
- Return 200 OK if all of the critical services are running
- Return 503 if a critical service is down
It's important that this check only covers critical services - in other words, something which prevents your application from functioning outright if it's missing. Remember that if it's a problem with an external service, it's possible all nodes in the load balanced rotation could report the same error. That means they'll all be taken out of rotation, and you have no application. So you only want this to happen in the case you genuinely have no application: the content database is down, or something similarly disruptive. Smaller outages are better handled in application code (although if you start getting into more complex adaptively weighted load balancing, you can tell the load balancer to prefer routing traffic to nodes that are 100% operational where possible).
A good health check means traffic is only routed to a server that can actually handle it, and goes a significant way toward providing HA guarantees and early failover of web applications. It's also easy to add to an existing application; all you need is a good idea of what comprises the application stack to write a meaningful health check.
Image by Nikodem Nijaki CC-SA 3.0